As someone deeply involved with data manipulation and analysis, I’ve always been intrigued by the nuances of data types, especially within tools like Power Query. It’s fascinating to see how different platforms handle the underlying structure of our data. Today, I want to share some observations about integer data types in Dataflows Gen2 within Microsoft Fabric, building on my explorations in Power Query.
In Power Query, those of us working with data transformations are familiar with the concept of data types. When dealing with numbers, particularly integers, Power Query offers types like Int8.Type, Int16.Type, Int32.Type, and Int64.Type. While the menus often simply display “(Whole Number)”, Power Query internally defaults to Int64.Type. This default ensures a wide range of values can be accommodated, both positive and negative.
To illustrate this, let’s consider an example using Int8.Type, which has a value range from -127 to +127. If we attempt to input a value outside this range, like 128, Power Query’s behavior becomes apparent.
let Source = #table( type table [Int8 = Int8.Type], List.Transform({-127..128}, each {_}) ) in SourceWhen this code is executed across Power Query hosts like Excel or Power BI, you’ll notice that while 256 rows are processed, one error is flagged. This error occurs because the 256th row (containing the value 128) exceeds the allowable limit for an 8-bit integer. Interestingly, Power Query still creates the row in the table object, but populates it with an empty value, as indicated by the icon in the interface.
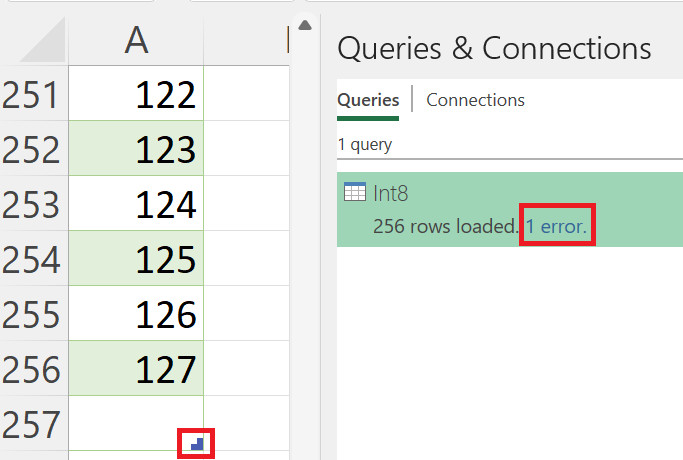 Power Query showing an error when a value exceeds the Int8.Type range
Power Query showing an error when a value exceeds the Int8.Type range
Now, let’s shift our focus to Dataflows Gen2 in Microsoft Fabric. A key difference here is the storage format: Dataflows Gen2 outputs data in Delta format (Parquet). This brings in a different set of data types, notably IntegerType() and LongType(). This led me to investigate how Dataflows Gen2 handles these types. My main question was: “Will Dataflows Gen2 intelligently utilize IntegerType for 32-bit or smaller integers, or will it default to LongType for all integer columns?”
To test this, I created a simple Dataflows Gen2 query with columns defined for each integer type: Int8, Int16, Int32, and Int64, and inserted a sample row of data.
let Source = #table( type table [Int8 = Int8.Type, Int16 = Int16.Type, Int32.Type, Int64.Type], {{1, 100, 1000, 1000000}} ) in SourceBy examining the schema of the resulting Delta table using a notebook and the df.schema operation, the answer became clear. Dataflows Gen2, in this scenario, stored all integer columns as LongType(). This means that even when smaller integer types are specified in the Power Query definition, the underlying Delta table utilizes LongType, capable of handling a much larger range of integer values.
While this behavior might seem like an over-provisioning of data types, it ensures maximum compatibility and prevents potential overflow issues. As noted by experts and discussed in articles like this one on PySpark data types, there are performance and optimization implications to consider when choosing data types in distributed data processing environments. Understanding how Dataflows Gen2 defaults to LongType is crucial for anyone designing data solutions on Microsoft Fabric.
In conclusion, while Power Query provides a range of integer type options, Dataflows Gen2, leveraging Delta format, appears to default to LongType for integer storage. This is an important characteristic to be aware of when building data pipelines and considering the long-term performance and efficiency of your Microsoft Fabric solutions.
